What is Tapdata?
Tapdata is a live data platform designed to connect data silos and provide fresh data to the downstream operational applications & operational analytics.
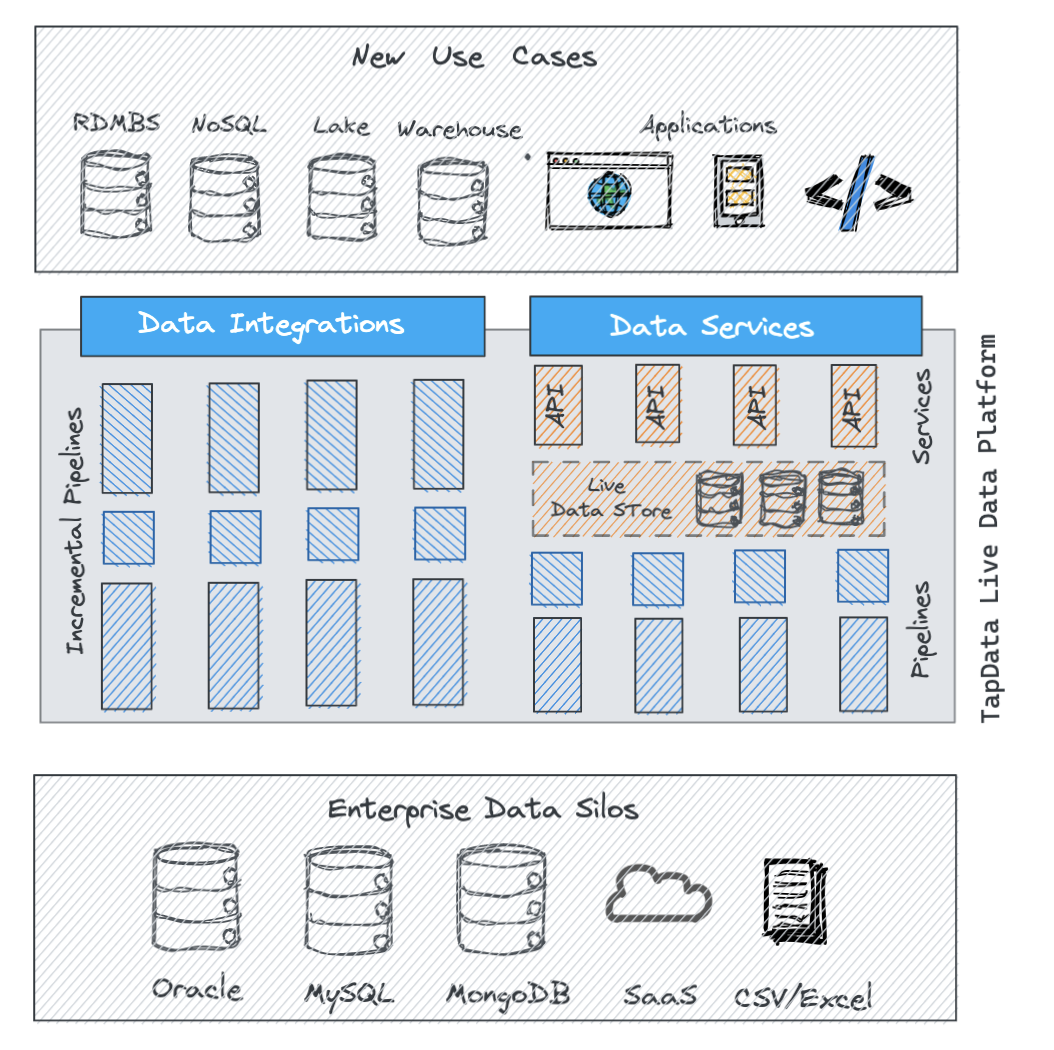
Tapdata provides two ways to achieve this: Live Data Integration and Live Data Service.
Live Data Integration is supported by Tapdata’s real time data pipelines based on CDC technology, where you can easily connect and capture all the data plus all the changes from disparate data sources, without any custom coding. Tapdata supports many data sources out of box, including dozens of popular databases, you may also use Tapdata’s PDK(Plugin Development Kit) quickly add your own data sources.
Live Data Service is Tapdata’s modern approach to the old data integration problem: streaming data into a centralized data store(currently powered by MongoDB), then serving the data via RESTful API. These APIs are created on-demand, and because they’re served by the horizontally scalable, high performant and modern database(instead of source systems), the number of ETL jobs, the performance impact to the source systems, are hence greatly reduced.
As an alternative, if your data source allows, you may also create data APIs directly from source databases such as Oracle, MySQL, SQLServer etc.
The term “live” has two meanings:
-
When you are using Live Data Integrations, Tapdata will collect data in a “live” mode means it will listen for the changes on the source database and capture the change immediately and send it to the pipeline for processing and downstream consumption. Sometime this is called CDC technology. The data is always fresh and lively throughout the data pipeline.
-
When you are using Live Data Services, the backing data store is lively updated by Tapdata Live Data Integration pipelines and stays up-to-date with the source systems.
Primary Use Cases
-
Heterogeneous Database Replication such as MySQL to MongoDB or ES
-
Real Time Data Pipelines, a better alternative to Kafka based data pipelines
-
Event-driven Applications, such as fraud detection or event notifications
-
Operational analytics where you need fresh data to make your insights reflect your business’s current state
How It Works
# Create Mysql DataSource
> Demo_Mysql = DataSource("mysql","Demo_Mysql").host("demo-mysql").port(3306).username('root').password('password').db('demo')
> Demo_Mysql.save()
# Create MongoDB DataSource
> Demo_Mongo = DataSource("mongodb","Demo_Mongo").uri("mongodb://root:password@demo-mongo:27017/demo?authSource=admin")
> Demo_Mongo.save()
# Create a job that transform the Customer table in Mysql to MongoDB and add/set filed 'updated' at the same time.
> Demo_job = Pipeline("Demo_job").readFrom(Demo_Mysql.Customer).js('record["updated"]=new Date() ;return record;').writeTo(Demo_Mongo.Customer-v1)
> Demo_job.start()
# Check the status of job
> show jobs
> monitor job Demo_job
# Check the log of job
> logs job Demo_job limit=5 tail=True
Features
- Build end to end real time data pipelines in minutes
- CDC based data replication, support dozens of popular data sources
- Low latency: sub-second performance compared to seconds with Kafka based solution
- Built-in incremental data verification
- At least once guarantee
- Developer friendly programmable pipeline API, managing data pipelines using code, not SQL
- Interactive shell, easily create, run and monitor pipelines and manage data services
- Javascript / Python UDF support
- Integration with Kafka as consumer or producer
- Code-less publish data API, support parameter
- Horizontal scaling
- Highly available pipelines
For more details and latest updates, see Tapdata docs and release notes.
More Use Cases: Who & When Can Use Tapdata
Application Develoepers
Tapdata can be used by Application developers in following use cases:
- 「Coming soon」Automatica API backend (Backend as a service) for data CRUD operations
- Code-less CQRS implementation
- Code-less RDBMS caching solution
- Code-less Producer / Consumer for Kafka
- Mainframe offloading
- Implement CQRS pattern
- Full text search / Graph search
Data Engineers or Data Analysts
For data engineers or data analysts, Tapdata can be used as a modern, general purpose, low code ETL platform for various data sync, processing or data modeling activities.
- Data extract / transform / load
- Data processing for data warehouse
- Data modeling
- Kafka-based data integration alternative
- Event streaming platform
DBAs / System Engineers
Tapdata can be used by DBAs in following use cases:
- Heterogeneous database replication
- Real time backup
- Database HA
- Database clustering
- Disaster Recovery strategy
- Sync to cloud or cross cloud data replication
Data Steward
Tapdata can be used by data stewards in following possible scenarios(Road map feature):
- Build an enterprise master data management platform, either as a hub or transactional type
- As a metadata management solution
- As a data as a service platform to facilitate fast data distribution to BUs
Road Map
- More pre-built processors
- Aggregation framework on data pipeline
- Pluggable Storage API - Support additional database for storage solution
- Open metadata compatibility
Community
You can join these groups and chats to discuss and ask Tapdata related questions:
{kind=link}
In addition, you may enjoy following:
- Question in the Github Issues
- The Tapdata Team Blog
For support, please contact Tapdata. (todo: a brand new contact us page)
Quick start
To start using Tapdata
See Quick Start Guide.
Use cases
License
Tapdata is under the SSPL v1 license.